In this post, I want to bridge the gap between abstract vector spaces (which are the mathematical foundation of linear algebra) and matrix multiplication (which is the linear algebra most of us are familiar with). To do this, we will restrict ourselves to a specific example of a vector space – the Euclidean space. Unlike the typical 101 course in linear algebra, I will avoid talking about solving systems of equations in this post. While solving systems of equations served as the historical precedent1 for mathematicians to begin work on linear algebra, it is today an application, and not the foundation of linear algebra.
For this post, I expect that the reader has come across concepts like linear independence and orthogonal vectors before, and can consult Wikipedia for anything that looks new to them.
The Recipe for $\mathbb R^n$
We write $\mathbb R^n$ as a short-hand for $\mathbb R \times \mathbb R \times \dots \times \mathbb R$, the set of sequences (of length $n$) of real numbers. For notational convenience, we also use ‘$\mathbb R^n$’ to denote the $n$-dimensional Euclidean space, which is not just a set of objects, but a set of objects that has a particular structure. In order to arrive at this structure, we need to introduce the following mathematical ingredients, in order:
-
Scalars: Defined as the elements of a set (technically, a field ) which has two binary operations called addition and multiplication. We choose $\mathbb R$ (the real numbers) as the set of scalars.
-
Vectors: For some integer $n > 0$, we define the set of vectors as $\mathbb R^n$. The vectors have the vector addition and scalar multiplication operations. These operations satisfy certain axioms which ensure that the addition and multiplication operations behave like they ought to.
-
Basis: We need to pick a basis $\mathcal B$ for $\mathbb R^n$, which is a set of vectors $\lbrace \mathbf b_1, \mathbf b_2, \dots, \mathbf b_n \rbrace$, where $\mathbf b_i \in \mathbb R^n$, such that every vector $\mathbf v\in \mathbb R^n$ can be uniquely expressed as a linear combination of the basis vectors. This means that there is a unique sequence of real numbers $v^{(\mathcal B)}_1,v^{(\mathcal B)}_2, \dots, v^{(\mathcal B)}_n \in \mathbb R$ satisfying
\[ \mathbf v= v^{(\mathcal B)}_1 \mathbf b_1 + v^{(\mathcal B)}_2 \mathbf b_2 + \dots + v^{(\mathcal B)}_n \mathbf b_n \]
- Inner Product: For vectors $\mathbf v$ and $\mathbf w$, $\langle \mathbf v,\mathbf w \rangle$ is called the inner product of $\mathbf v$ and $\mathbf w$; it maps each pair of vectors to a scalar. The usual inner product that we define for $\mathbb R^n$ is sometimes called the dot product. An inner product imparts geometry to its vector space, because we can use it to define the ’length’ of a vector $\mathbf v$ as $\sqrt{\langle \mathbf v, \mathbf v\rangle }$, and ‘angles’ between vectors as
\[\theta(\mathbf v,\mathbf w) = \arccos\left(\frac{\langle \mathbf v,\mathbf w \rangle}{\sqrt{\langle \mathbf v, \mathbf v\rangle \langle \mathbf w, \mathbf w\rangle}}\right)\]
- Orthonormal Basis: If the basis $\mathcal B$ is such that $\langle \mathbf b_i, \mathbf b_j\rangle = 1$ when $i=j$ and $0$ otherwise, we call it an orthonormal basis. Because of how we defined $\theta$, $\langle \mathbf b_i, \mathbf b_j\rangle = 0$ implies that $\theta(\mathbf b_i, \mathbf b_j)=90^\circ$.
We have introduced ingredients 3, 4, and 5 in a very specific order. Let’s see why that is so.
The Standard Basis
Mathematicians avoid picking the basis $\mathcal B$ explicitly. Often, they start their analysis with the following (implied) disclaimer:
“We have chosen some basis, $\mathcal B \subseteq \mathbb R^n$, but the specific choice of basis does not matter for what we’re about to show.”
Basically, don’t worry too much about which basis we chose, just know that we have chosen one. Once a basis $\mathcal B = \lbrace \mathbf b_1, \mathbf b_2, \dots, \mathbf b_n\rbrace$ has been chosen, each vector $\mathbf v\in \mathbb R ^n$ can be uniquely expressed by a sequence of $n$ coefficients, $\left(v^{(\mathcal B)}_i\right)_{i=1}^n$, such that $\mathbf v=\sum_{i=1}^n v^{(\mathcal B)}_i \mathbf b_i$. Thus, the vector $\mathbf v$ can be expressed unambiguously using the following, more familiar notation:
\[\begin{bmatrix} v^{(\mathcal B)}_1\\ v^{(\mathcal B)}_2\\ \vdots\\ v^{(\mathcal B)}_n \end{bmatrix}\]
Note that this notation involves both a vector $\mathbf v$ and a basis $\mathcal B$. Choosing a different basis $\mathcal B' = \lbrace \mathbf b'_1, \mathbf b'_2, \dots, \mathbf b'_n \rbrace$ changes the coefficients of the vector to $\left(v^{(\mathcal B')}_i\right)_{i=1}^n$, but it does not change the vector itself. For bases $\mathcal B$ and $\mathcal B'$, we have
\[\mathbf v=\sum_{i=1}^n v^{(\mathcal B)}_i \mathbf b_i =\sum_{i=1}^n v^{(\mathcal B')}_i \mathbf b'_i\]
At a glance, this assertion might appear to contradict with the following observation:
\[\begin{bmatrix} v^{(\mathcal B)}_1\\ v^{(\mathcal B)}_2\\ \vdots\\ v^{(\mathcal B)}_n \end{bmatrix} \neq \begin{bmatrix} v^{(\mathcal B')}_1\\ v^{(\mathcal B')}_2\\ \vdots\\ v^{(\mathcal B')}_n \end{bmatrix} \]
This is purely because of the ‘square-bracket’ notation. Before we write vectors in their ‘square-bracket’ form, we must not only choose a basis, but also fix a basis. Let’s fix a basis $\mathcal B$ for $\mathbb R^n$, which we call as the standard basis. Now, for $c_1,c_2,\dots,c_n\in\mathbb R$, the ‘square-bracket’ notation
\[\begin{bmatrix} c_1\\ c_2\\ \vdots\\ c_n \end{bmatrix} \]
refers unambiguously to the vector $\sum_{i=1}^n c_i \mathbf b_i$. Therefore, observe that
\[ \begin{bmatrix} v^{(\mathcal B)}_1\\ v^{(\mathcal B)}_2\\ \vdots\\ v^{(\mathcal B)}_n \end{bmatrix} \neq \begin{bmatrix} v^{(\mathcal B')}_1\\ v^{(\mathcal B')}_2\\ \vdots\\ v^{(\mathcal B')}_n \end{bmatrix} \text{ \ because\ } \sum_{i=1}^n v^{(\mathcal B)}_i \mathbf b_i \neq \sum_{i=1}^n v^{(\mathcal B')}_i \mathbf b_i \]
Thus, there is a distinction between the vector itself and its representation in the standard basis $\mathcal B$; the ‘square-bracket’ notation gives us the latter, and it is our job to infer the former. Observe that the standard basis vectors $\mathbf b_i$ can themselves be represented in the ‘square-bracket’ notation, as
\[ \mathcal B = \left\lbrace \begin{bmatrix} 1\\ 0\\ 0\\ \vdots\\ 0 \end{bmatrix}, \begin{bmatrix} 0\\ 1\\ 0\\ \vdots\\ 0 \end{bmatrix}, \begin{bmatrix} 0\\ 0\\ 1\\ \vdots\\ 0 \end{bmatrix}, \dots, \begin{bmatrix} 0\\ 0\\ 0\\ \vdots\\ 1 \end{bmatrix} \right\rbrace \]
Notice that we can do our usual linear algebra stuff without actually specifying the contents of $\mathcal B$, as long as we fix $\mathcal B$ and don’t change it thereafter. Nothing about the orthogonality of $\mathbf b_1, \mathbf b_2, \dots, \mathbf b_n$ has been said yet, because we need an inner product to even define what orthogonality means.
The Dot Product
We can now define an inner product in terms of the standard basis $\mathcal B$. For vectors $\mathbf v, \mathbf w \in \mathbb R^n$, we define $\langle \mathbf v, \mathbf w\rangle = \sum_{i=1}^n v^{(\mathcal B)}_i w^{(\mathcal B)}_i$, which we call as the dot product. In the matrix multiplication or “square-bracket” notation, we write this as
\[ \begin{bmatrix} v^{(\mathcal B)}_1 & v^{(\mathcal B)}_2 & v^{(\mathcal B)}_3 & \dots & v^{(\mathcal B)}_n \end{bmatrix} \begin{bmatrix} w^{(\mathcal B)}_1 \\ w^{(\mathcal B)}_2 \\ w^{(\mathcal B)}_3 \\ \vdots \\ w^{(\mathcal B)}_n \end{bmatrix} \]
Note that we are defining the inner product this way. Importantly, we are defining it in a way that makes the basis vectors, $\mathbf b_1, \mathbf b_2, \dots, \mathbf b_n$, orthonormal. If we had instead defined the inner product as $\langle \mathbf v, \mathbf w\rangle = \sum_{i=1}^n v^{(\mathcal B')}_i w^{(\mathcal B')}_i$, then the basis $\mathcal B'$ becomes orthonormal (under this new definition of orthonormality). Thus, any basis can be ‘made orthonormal’ by redefining the inner product appropriately.
The ‘row vector’ corresponding to $\mathbf v$ is usually called the transpose of $\mathbf v$, and is denoted as $\mathbf v^\intercal$. Strictly speaking, it is a linear map $\mathbf v^\intercal:\mathbb R^n \rightarrow \mathbb R$ (See dual space if you’re curious about what’s going on here.)
Linear Algebra
Let $V$ and $W$ be vector spaces. They could be Euclidean spaces, but they could also be subspaces of Euclidean spaces (recall that a flat plane passing through the origin is a subspace of $\mathbb R^3$), or something else entirely. A linear map or a linear transformation is a map $f:V\rightarrow W$ which transforms each vector in $V$ to a vector in $W$ in a linear manner. This means that for $\mathbf u,\mathbf v\in V$ and $a\in \mathbb R$,
\[f(\mathbf u + \mathbf v)= f(\mathbf u)+f(\mathbf v)\]
and
\[f(a\mathbf u)= af(\mathbf u)\]
Notably, we have $f(0 \mathbf u) = f(\mathbf 0) = \mathbf 0$. The word ’linear’ comes from the special case of the linear map, $f:\mathbb R \rightarrow \mathbb R$; the plot of this function is a straight line passing through the origin. This is also where the ’linear’ in linear algebra comes from: it is the study of linear maps in vector spaces.
Now here’s where abstract linear algebra starts developing into the ‘matrix multiplication’ version of linear algebra:
Any linear map $f:V \rightarrow W$ between two finite-dimensional vector spaces $V$ and $W$ can be represented as a matrix.
To see this, let’s start by choosing bases for $V$ and $W$, denoted as $\mathcal B^{(V)} = \lbrace \mathbf b^{(V)}_1, \mathbf b^{(V)}_2, \dots, \mathbf b^{(V)}_n \rbrace$ and $\mathcal B^{(W)} = \lbrace \mathbf b^{(W)}_1, \mathbf b^{(W)}_2, \dots, \mathbf b^{(W)}_m \rbrace$, where $n$ and $m$ are the dimensions of $V$ and $W$. For simplicity, we will assume that the scalars in $V$ and $W$ are real numbers (as opposed to, say, one of them being a complex vector space).
Observe that $f(\mathbf b^{(V)}_i)\in W$. Each vector in the basis of $V$ is mapped (linearly) to a corresponding vector in $W$. This means that we can express each of the mapped basis vectors $f(\mathbf b^{(V)}_i)$ as a linear combination:
\[ \begin{align*} f(\mathbf b^{(V)}_i) &= F_{1i} \mathbf b^{(W)}_1 +F_{2i} \mathbf b^{(W)}_2 + \dots + F_{mi} \mathbf b^{(W)}_m \\ &= \sum_{j=1}^{m} F_{ji} \mathbf b^{(W)}_j \end{align*} \]
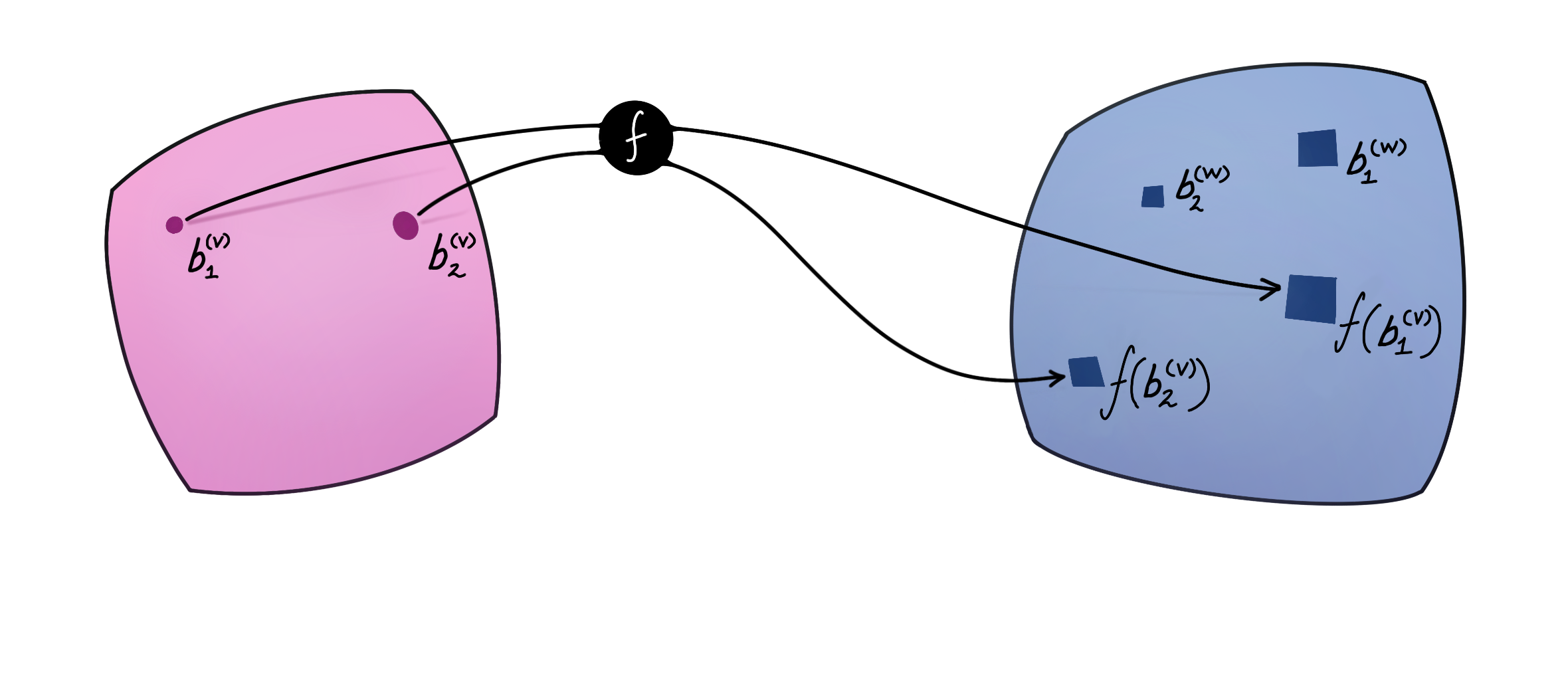
where $F_{ji} \in \mathbb R$ are unique. Now consider the action of $f$ on an arbitrary vector $\mathbf v \in V$ that is not a basis vector. We first write $\mathbf v$ as the linear combination
\[ \mathbf v = v_1 \mathbf b^{(V)}_1 + v_2 \mathbf b^{(V)}_2 + \dots + v_n \mathbf b^{(V)}_n \in V \]
Due to the properties of a linear transformation (i.e., its linearity), we have the following algebra:
\[ \begin{align*} f(\mathbf v) &= f\left(v_1 \mathbf b^{(V)}_1 + v_2 \mathbf b^{(V)}_2 + \dots + v_n \mathbf b^{(V)}_n\right)\\ &= f\big(v_1 \mathbf b^{(V)}_1\big) + f\big(v_2 \mathbf b^{(V)}_2\big) + \dots + f\big(v_n \mathbf b^{(V)}_n\big)\\ &= v_1 f\big(\mathbf b^{(V)}_1\big) + v_2 f\big( \mathbf b^{(V)}_2\big) + \dots + v_n f\big(\mathbf b^{(V)}_n\big)\\ \end{align*} \]
Thus, the action of $f$ on the vector $\mathbf v$ indirectly depends on the action of $f$ on the basis vectors. We have already seen where $f$ takes the basis vectors of $V$, so let’s plug that in:
\[ \begin{align*} f(\mathbf v) &= \sum_{i=1}^n v_i f(\mathbf b^{(V)}_i) \\&= \sum_{i=1}^n v_i \sum_{j=1}^{m} F_{ji} \mathbf b^{(W)}_j \\&= \sum_{j=1}^{m} \sum_{i=1}^n v_i F_{ji} \mathbf b^{(W)}_j\\ &= \sum_{i=1}^n v_i F_{1i} \mathbf b^{(W)}_1 + \sum_{i=1}^n v_i F_{2i} \mathbf b^{(W)}_2 + \dots + \sum_{i=1}^n v_i F_{mi} \mathbf b^{(W)}_m \end{align*} \]
where $\sum_{i=1}^n v_i F_{1i}$ is the coefficient of $f(\mathbf v)$ corresponding to the basis vector $\mathbf b_1^{(W)}$. From here on, it’s only a matter of noticing that we can represent this entire relationship using the “matrix-multiplication” operation:
\[ \begin{bmatrix} \sum_{i=1}^n v_i F_{1i}\\ \sum_{i=1}^n v_i F_{2i}\\ \vdots\\ \sum_{i=1}^n v_i F_{mi} \end{bmatrix} = \begin{bmatrix} F_{11} & F_{12} & & \\ F_{21} & F_{22} & & \\ & & \ddots & &\\ & & & F_{mn} \end{bmatrix} \begin{bmatrix} v_1\\v_2\\ \vdots \\ v_n \end{bmatrix} \]
which we can write as “$\mathbf w = \mathbf F \mathbf v$”. There is a subtlety here: on the left-hand side of this equation, we assume the ‘standard basis’ to be $\mathcal B^{(W)}$, whereas for the vector on the right we were using the standard basis $\mathcal B^{(V)}$. Thus, we need to fix both bases (one for $V$ and one for $W$) before the linear transformation can be written, unambiguously, as a matrix multiplication. If the dimensions of $V$ and $W$ are the same, we may pick the same basis on either side. Observe that we never used the inner product while talking about linear transformations, and thus, we do not claim whether the bases we used above are orthonormal. They are simply linearly independent, as all bases are. In case the basis $\mathcal B^{(V)}$ is orthonormal, then this just means that we can find the coefficients $v_1, \dots, v_n$ very easily: $v_i = \langle \mathbf v, \mathbf b_i \rangle$.
Orthonormal Transformations
Let’s now study $\mathbb R^n$ as an inner product space, which is the vector space $\mathbb R^n$ combined with the usual inner product – the dot product.
We say that a matrix $\mathbf U$ is orthonormal if $\mathbf U^\intercal \mathbf U = \mathbf U \mathbf U^\intercal = \mathbf I$. This is closely related to how we say that a set of basis vectors is orthonormal: Suppose $\mathcal B$ is an orthonormal basis, then so is the basis $\mathcal B_U = \lbrace \mathbf U \mathbf b_1, \mathbf U \mathbf b_2, \dots, \mathbf U \mathbf b_n \rbrace$, because
\[ \langle \mathbf U\mathbf b_i, \mathbf U\mathbf b_j \rangle = \mathbf b_i^\intercal \mathbf U^\intercal \mathbf U \mathbf b_j = \mathbf b_i ^\intercal \mathbf b_j = \langle \mathbf b_i, \mathbf b_j \rangle \]
Let the underlying linear transformation corresponding to $\mathbf U$ be denoted as $g:V\rightarrow V$, with $\mathcal B$ being an orthonormal basis for $V$. $\mathbf U$ is the representation of $g$ in the matrix multiplication form, with respect to the basis $\mathcal B$. Recall the algebra we did earlier:
\[g(\mathbf v) = g\Big( \sum_{i=1}^n v_i\mathbf b_i\Big) = \sum_{i=1}^n v_i g(\mathbf b_i)\]
where we know that the set $\lbrace g(\mathbf b_1), g(\mathbf b_2), \dots g(\mathbf b_n)\rbrace = \mathcal B_U$ is orthonormal. Thus, $\mathbf v$ and $g(\mathbf v)$ have the same representation (given by the numbers $v_1, v_2, \dots v_n$) under $\mathcal B$ and $\mathcal B_U$. This is why we can call $\mathbf U$ a “change of basis” – it keeps the vector’s representation the same, but changes the (orthonormal) basis that we are representing it in. Even if the vector’s representation is same in either basis, the vector itself is changing under $\mathbf U$:
\[ \mathbf v = \sum_{i=1}^{n} v_i \mathbf b_i \neq \sum_{i=1}^{n} v_i g(\mathbf b_i) = g(\mathbf v) \]
Alternatively, we can re-express the transformed vector in the original basis $\mathcal B$, in which case $g$ is interpreted as purely a transformation of the vector’s components while keeping the basis fixed. This duality in how we can view a ‘change of basis’ has been explored more in this article .
Preserving Structure and Dimension
Any transformation on a mathematical space that preserves its structure (i.e., the relationships of its objects to each other) turns out to be quite special. Linear transformations preserve the structure of a vector space, because any three vectors $\mathbf u,\mathbf v,\mathbf w\in V$ which have the relationship $\mathbf u + \mathbf v = \mathbf w$ are still related to each other after the transformation: $f(\mathbf u) + f(\mathbf v) = f(\mathbf w)$.3
Structure-preserving transformations which are also invertible are called as isomorphisms . We can show that the inverse $f^{-1}:W\rightarrow V$, if it exists, must also be a linear transformation. Thus, $f^{-1}$ can be represented as a matrix. Invertible linear transformations are the isomorphisms of vector spaces. Invertible matrices are “square” because a linear transformation can only be invertible if its domain and codomain have the same dimension. 4
Similarly, orthonormal matrices represent the structure-preserving transformations in inner-product spaces : a set of vectors that is orthonormal before the transformation remains orthonormal after the transformation, where orthonormality is defined via the dot product. They are also the isomorphisms of inner-product spaces, because the inverse of an orthonormal matrix $\mathbf U$ always exists $--$ it is $\mathbf U^\intercal$.
Mathematicians almost always (or perhaps, always) study mathematical objects “up to isomorphism”. This means that we are not studying any particular mathematical object, but rather we are simultaneously studying all of the mathematical objects that are isomorphic to each other. This is why we do not need to specify which basis we are using as the standard basis: it simply does not matter, as long as we fix this basis and stay consistent. This is analogous to how we may need to fix the origin when studying ‘displacement’ and ‘speed’ in physics. Choosing a different origin does not change the physical phenomenon, it only changes our description of it.
-
See this for the historical context of matrix multiplication, which is different from (but essentially the same as) modern mathematics’ treatment of it. ↩︎
-
The words every and unique can be compared to the concepts of surjectivity (also called as onto) and injectivity (also called as one-one), respectively. A function between two sets is invertible if and only if it is both surjective and injective. The ‘sets’ here are the vectors and their representations. ↩︎
-
There is an abuse (or rather, a reuse) of notation here; note that the vector addition in $W$ may be different from the vector addition in $V$, though we denote both as ‘$+$’ for convenience. We also use ‘$+$’ to denote the scalar addition operation. ↩︎
-
An invertible function between sets must be injective and surjective. If the dimension of $W$ is greater than that of $V$, then $f$ cannot be surjective. If the dimension of $V$ is greater, then $f$ cannot be injective. ↩︎